分享至
LLM無法直接理解文字,因此我們需要先將文字轉換成數字(Token)。Tokenization就是這個轉換過程,且不同模型會有不同的規則。
我們可以用tokenizer.vocab_size來查看欲使用的語言模型中token的數量,看它有多少token可以在文字接龍時進行選擇。
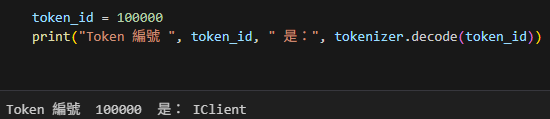
每一個token都有一個編號(從0開始)。我們可以用tokenizer.decode這個函數將token編號轉成對應的文字。
IT邦幫忙

 妤
妤

 iThome鐵人賽
iThome鐵人賽